Meta SAM Audio 教學課程
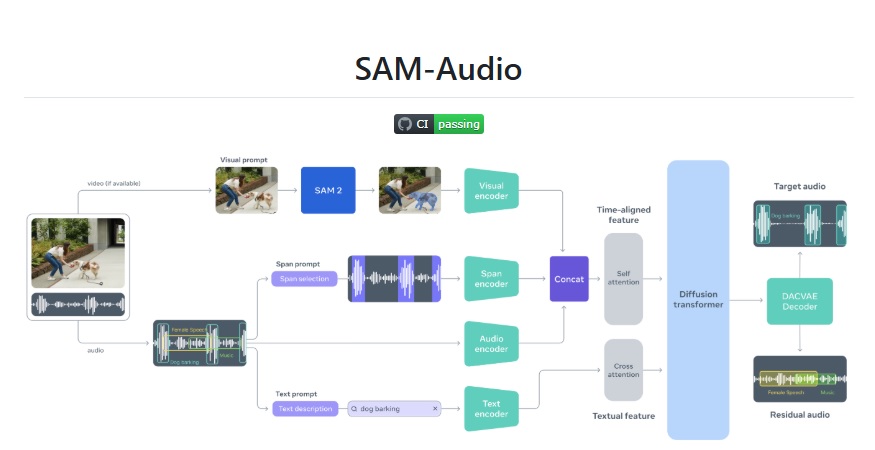
課程名稱:Meta SAM Audio 多模態音訊分離速成班
課程時長:2 小時(120 分鐘)
目標對象:音訊工程師、音樂製作人、Podcast 創作者、影片後製師、AI 開發者與內容運營者。
學習目標:系統掌握 SAM Audio 的生成式架構、多模態提示範式(文字、視覺、時間)與端到端分離管線,實現從混合音訊中精準抽取目標 Stem 的生產流程。學員將具備評估 BSS Eval 指標、API 整合與商用部署能力,輸出專業級音軌資產,提升後製效率 70%。
課程大綱
模組 1:SAM Audio 架構解析與應用定位(20 分鐘)
-
技術棧概述:PE-AV 感知編碼器、生成式 GAN 與時空注意力機制。
-
三維提示範式:文字提示(Text Prompt)、視覺提示(Visual Prompt)、時間區段(Time Span Prompt)。
-
商用場景:音樂 Stem 分離、Podcast 噪音過濾、影片音效修復、無障礙輔具。
-
實作啟動:Hugging Face Playground 登入、基準音檔上傳(10 分鐘)。
模組 2:環境部署與 API 接入(15 分鐘)
-
資源配置:GitHub Repo Clone、ONNX Runtime 安裝、GPU 加速(RTX 40 系列)。
-
SDK 整合:Python RESTful API 呼叫、批量分離管線(Batch Inference)。
-
效能基準:SI-SDR、Purity Score 監控與 SAM Audio-Bench 評測。
-
實作:本地環境初始化、單軌分離測試(5 分鐘)。
模組 3:文字與時間提示分離實作(25 分鐘)
-
介面導覽:提示輸入、波形視覺化、Stem 輸出軌道。
-
提示工程:語意嵌入優化(如「吉他撥弦 + 重低音」)、負提示防 artifact。
-
品質控制:SNR 提升、完整性保留、多輪迭代(Refinement Loop)。
-
實作:Podcast 過濾環境噪音、音樂軌道抽取(15 分鐘)。
模組 4:視覺提示與混合模式進階(25 分鐘)
-
視覺互動:影片點選發聲物件、時空對齊(Audio-Visual Alignment)。
-
混合提示:文字 + 視覺 + 時間組合,F1-Score 優化策略。
-
錯誤診斷:相似源干擾、邊緣崩壞修復(Masking 技巧)。
-
實作:樂團影片分離單樂器、AR 空間聲源提取(15 分鐘)。
模組 5:生產管線優化與後製串接(20 分鐘)
-
批量工作流:Apache Airflow DAG、多版本 A/B 測試、Autoscaling。
-
後製整合:Adobe Audition 匯入、DaVinci Resolve Stem 插件。
-
評測與監控:SAM Audio Judge 自動評分、PSI 漂移偵測。
-
實作:端到端管線部署,處理 10 段混合音檔(10 分鐘)。
模組 6:治理框架、風險緩解與產業前瞻(15 分鐘)
-
合規治理:Deepfake 音訊水印、GDPR 隱私相容、內容審核 Filter。
-
成本 ROI:TCO 分析、Spot Instance 優化。
-
未來路線圖:SAM Audio 2.0 Agentic、多模態 RAG、即時串流。
-
總結與 Q&A:商用 POC 模板、社群資源(Hugging Face/Discord)。
*可選擇上門、到校、到企業等彈性小班AI教學模式
**以上AI課程由知名香港AI教學先行者 「香港AI學院」 提供課程內容及技術的支援,以確保 「AI課程」 高性價比的品質水平。
環球AI認證考試(AI Capability Evaluation,ACE)

> > 按此回到 「AI創業課程列表」